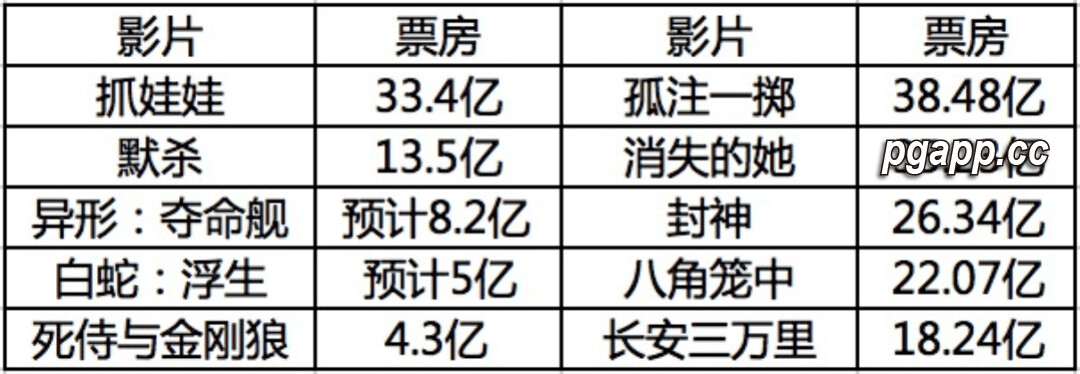
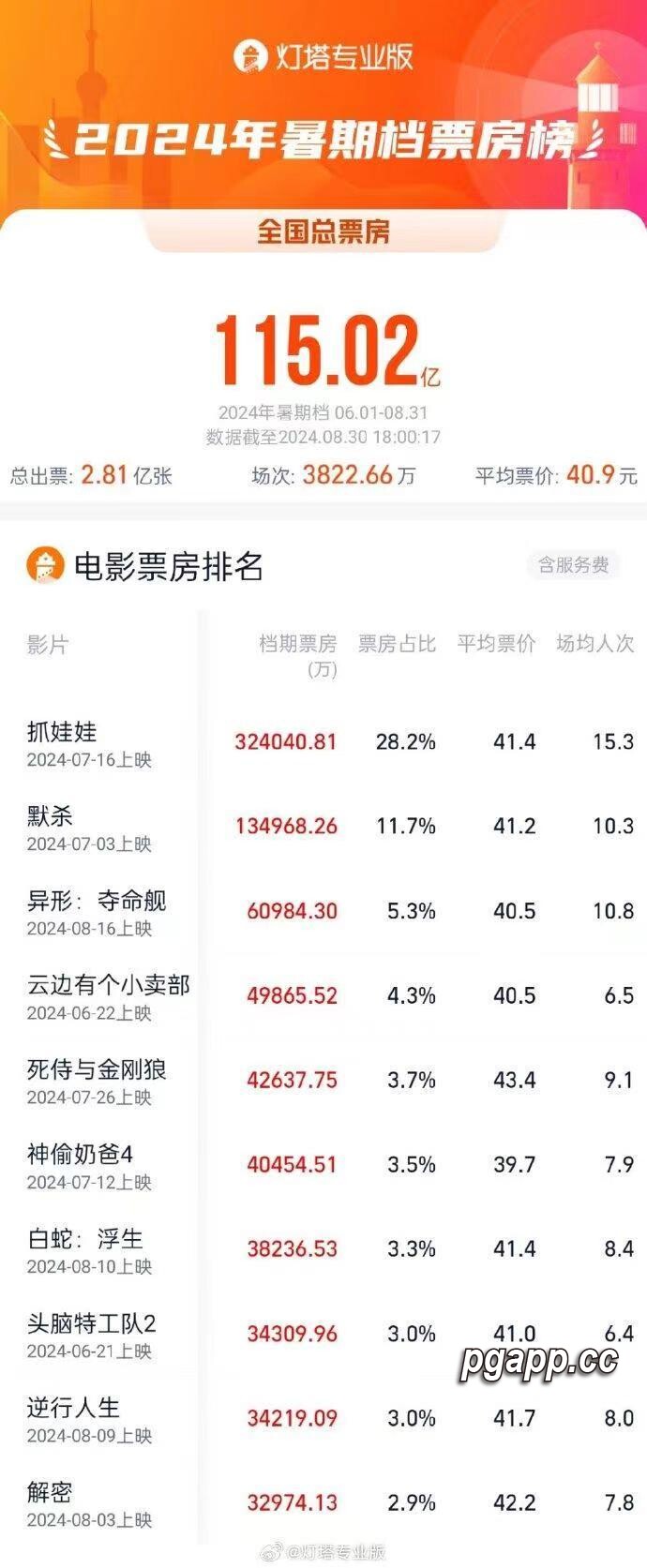
近日,谷歌以视频形式对外展示了其最新研发的大型语言模型——Gemini。这款产品在赋予机器识别文本的同时,更进一步推陈出新,实现了多模态识别的巨大突破,在与前代技术如GPT的竞争中,展现了其独到的优势。
多模态在这里并非简单的图文结合,而是指机器能够处理并理解包括语音、视频以及音乐在内的多种信息形式。通俗地说,你无需再局限于打字与AI交流,你可以使用语音给它下指令,你可以展示视频或图片让它分析,甚至你的涂鸦也能成为交流的媒介。
通过Google官方提供的演示视频可以看到,即使视频本身承认经过编辑,其所呈现的场景无疑是令人印象深刻的——一个更接近人类日常沟通习惯的AI。在Gemini的帮助下,用户将能够通过更为自然的方式与机器交互,从而达到更高效的沟通效果。
值得一提的是,谷歌进入这一领域拥有极为显著的优势。首先是人才的优势,据悉,谷歌此次投入了近1000人的团队致力于Gemini的开发,这支超大规模的人才队伍为产品的研发提供了坚实保障。
其次是场景与流量的优势。作为全球最大的互联网入口,谷歌拥有Gmail、Search、Chrome浏览器、安卓操作系统等多款全球知名产品。当大型模型与用户的使用场景紧密结合时,用户群体的实时反馈将极大促进AI产品的快速优化和迭代。
第三,数据和知识的优势。作为一家始于搜索服务的公司,谷歌在数据积累和知识把握方面拥有与生俱来的优越性,这对于训练大型模型来说至关重要。
四是搜索与AI的结合优势,谷歌借助自己强大的搜索技术,能够实时更新AI模型的知识库,保证AI输出的即时性和准确性。
第五,谷歌还拥有丰富的优质多模态语料资源。YouTube作为全球最大的视频分享平台,每天都有大量的视频内容及知识标签被上传。利用这些语料,谷歌的多模态技术将更具备学习和理解的广度和深度。
最后而且非常关键的一点是,谷歌拥有自己的人工智能芯片TPU,这种专为AI训练和推理设计的专用芯片将极大降低训练成本,提升运算效率。
对于创业者而言,谷歌的这一突破不仅仅是技术上的革新,也预示着未来人工智能领域中的巨大机遇。在业务流程与产品创新上,嵌入大模型的AI技术将为传统行业的变革带来新的视角,为创业者寻找垂直领域的机会提供了新的方向。
谷歌的Gemini模型在全球AI领域的地位无可置疑,其在多模态交流、数据资产、搜索能力三方面的整合潜力巨大,意味着它在跨越现有技术边界的同时,也为未来智能互联网发展的趋势设定了新基准。